
Всем кто ждал скидок на пополнение баланса!
Дорогие пользователи Archivarix, Поздравляем вас с наступающими праздниками и благодарим за то, что вы выбрали наш сервис для архивации и восстановления веб-сайтов!
Читать дальше…

6 лет Archivarix
Наступил момент, когда мы гордимся не только своими достижениями, но и вашим участием в этом пути. В этом году Archivarix празднует своё 6-летие, и в первую очередь мы хотели бы выразить огромную благодарность вам, нашим преданным пользователям.
Читать дальше…

Изменение цен
С 1 февраля 2023 года изменятся цены на восстановления и скачивания. Активируйте промо-код и получите бонус.
Читать дальше…


День рождения Archivarix
Наступило 4 года с тех пор, как 29 сентября 2017 мы сделали сервис Archivarix публичным. Ежедневно пользователи делают тысячи восстановлений. Количество серверов, которые распределяют между собой скачивания и обработку всегда превышает 40, а при нагрузке система самостоятельно подключает новые машины.
Читать дальше…
Что можно восстановить из веб архива?
Иногда наши пользователи спрашивают, почему сайт восстановился не полностью? Почему он не работает так, как хотелось бы? Известные проблемы при восстановлении сайтов из archive.org.
Читать дальше…

BLACKFRIDAY
С пятницы 27.11.2020 до понедельника 30.11.2020 действуют два жирных купона. Каждый из них даёт бонус на баланс в виде 20% или 50% от суммы вашего последнего или нового платежа.
Читать дальше…
День рождения Archivarix
З года назад, 29 сентября 2017 года заработал наш сервис по восстановлению сайтов из archive.org. Все эти 3 года мы непрерывно развивались, мы создали свою CMS, систему скачивания живых сайтов, значительно улучшили и ускорили алгоритм восстановления из Веб-архива и многое другое.
Читать дальше…

Archivarix.net - Архив веб-сайтов и система поиска.
Аналог Wayback Machine (web.archive.org). Сервис по поиску архивных копий сайтов. Данные за 1996 год. Полнотекстовый поиск.
В ближайшее время наша команда планирует запустить уникальный сервис, сочетающий в себе возможности интернет-архива и поисковой системы.
Читать дальше…
В ближайшее время наша команда планирует запустить уникальный сервис, сочетающий в себе возможности интернет-архива и поисковой системы.
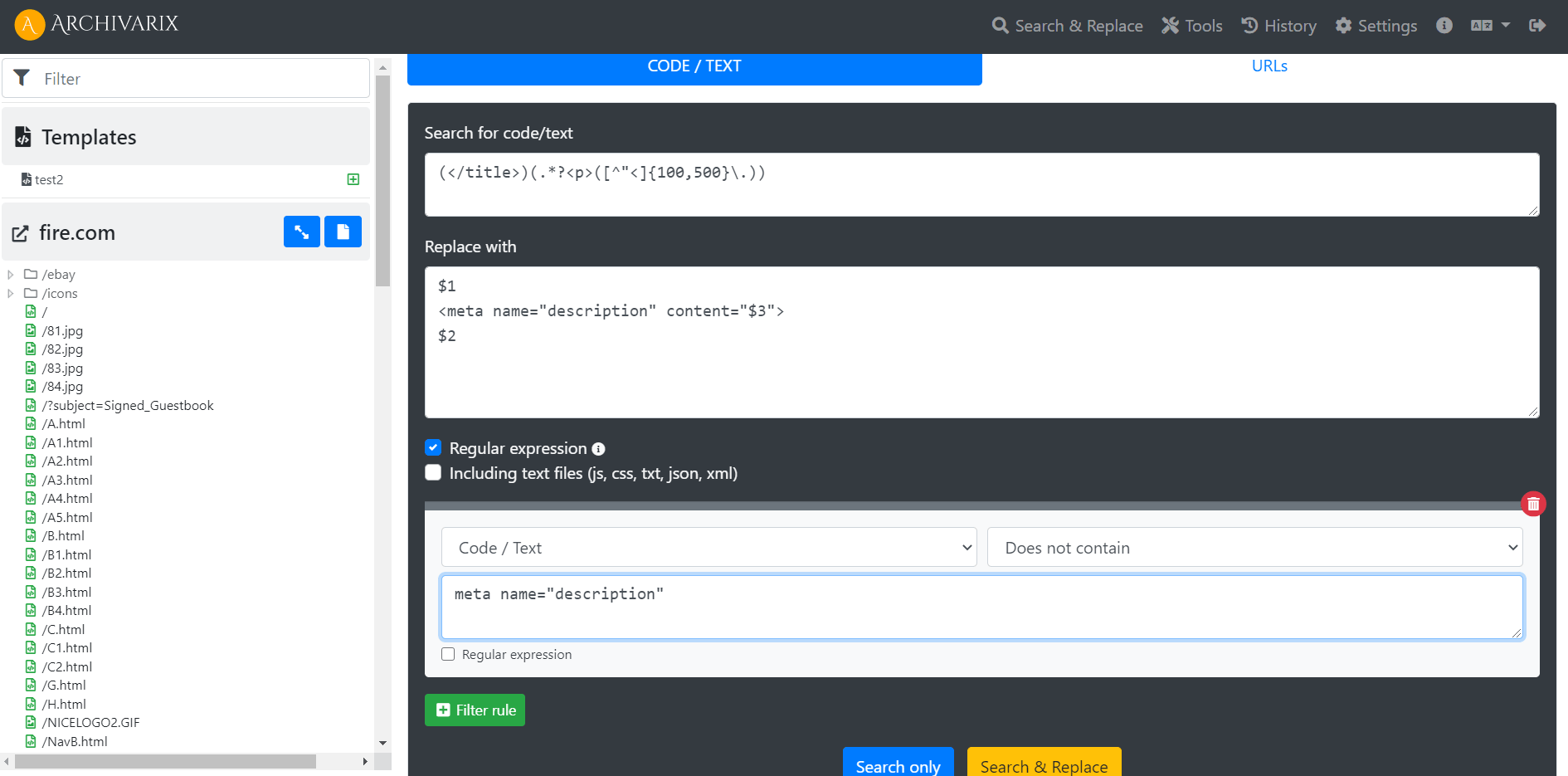
Примеры использование регулярных выражений в Archivarix CMS
Как генерировать метатег description на всех страницах сайта? Как сделать, так чтобы сайт работал не из корня, а из директории?
Читать дальше…

Как отобразить скрытые файлы в macOS
Как отобразить скрытые файлы в macOS. Отображение файлов начинающихся с точки, к примеру .htaсcess в macOS.
Читать дальше…
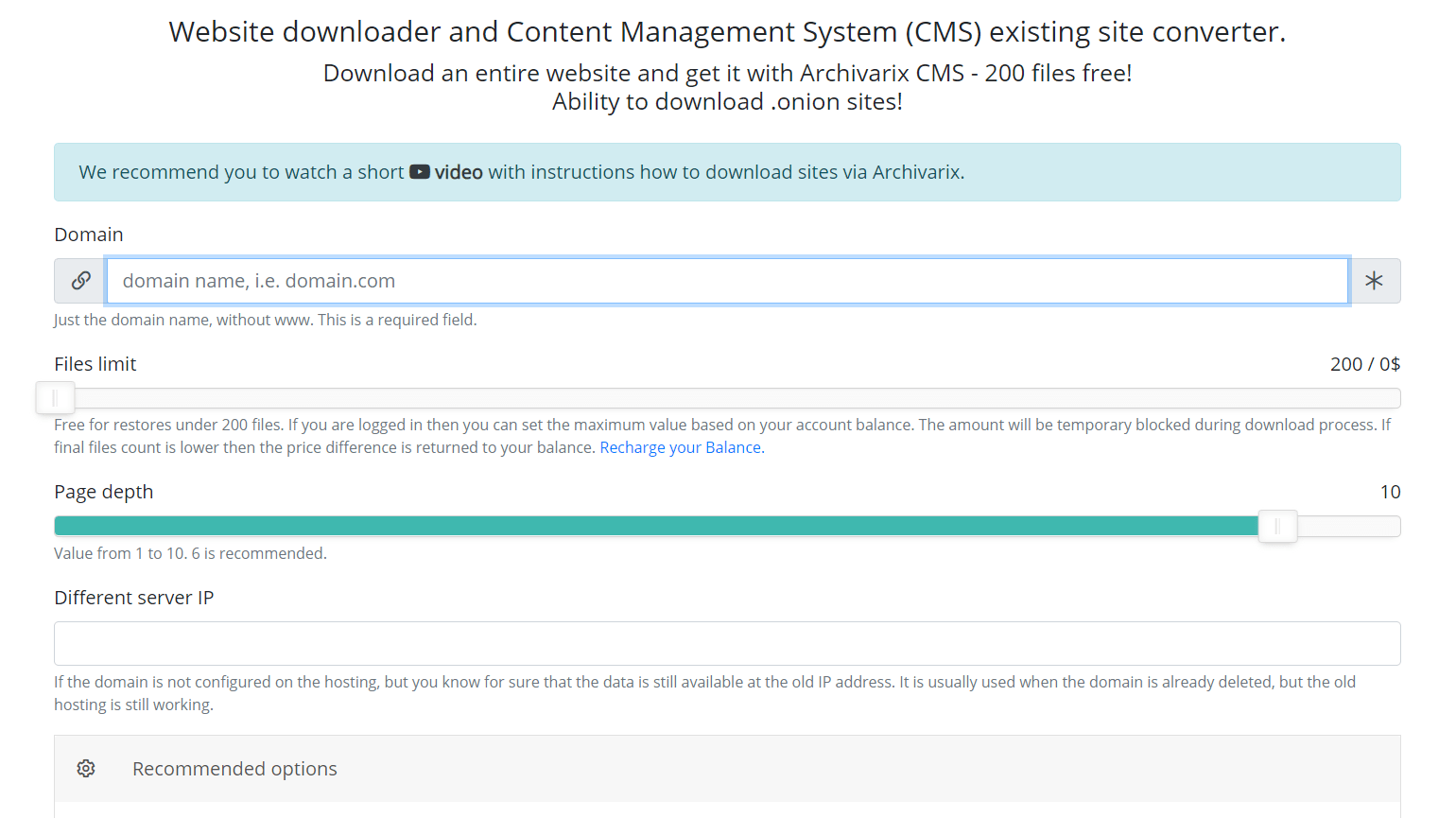
Система скачивания сайта. Как правильно выбрать количество файлов?
Наша система скачивания сайтов и конвертации их на нашу Archivarix CMS позволяет бесплатно скачивать до 200 файлов с сайта. Если на сайте файлов больше и все они нужны, то за эту услугу вы можете заплатить. Стоимость скачивания зависит от количества файлов. Как узнать сколько файлов действительно находится на сайте и сколько в итоге будет стоить скачать их всех?
Читать дальше…
Регулярные выражения, используемые в Archivarix CMS
В данной статье содержаться регулярные выражения, применяемые для поиска и замены в контенте сайтов, восстановленных с помощью системы Archivarix. Они не являются чем-то свойственным только этой системе. Если вы знаете регулярные выражения PHP, Perl, Java или других языков программирования, значит вы уже умеете пользоваться нашей системой поиска и замены. Если нет, то надеемся что эта статья вам поможет.
Читать дальше…
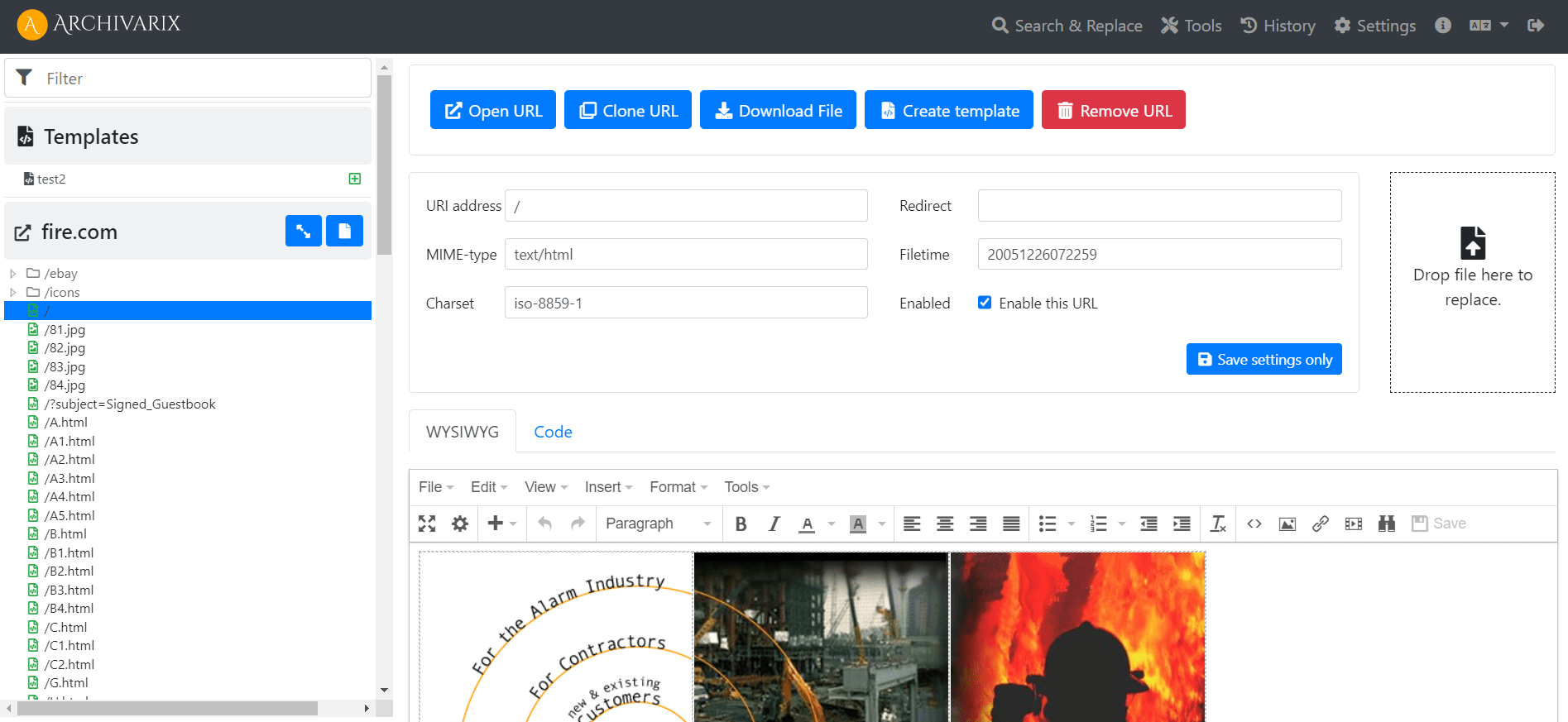
Простая и легкая Archivarix CMS. Редактор копированных сайтов.
Для того, чтобы вам было удобно редактировать восстановленные в нашей системе сайты, мы разработали простую Flat File CMS состоящую всего из одного небольшого файла. Не смотря на свой размер, эта CMS является мощным и универсальным инструментом для работы с вашими сайтами. В ней доступны все базовые возможности любой CMS, а так же специальные фишки для вебмастеров, создающих PBN на основе восстановленного из Веб Архива контента.
Читать дальше…
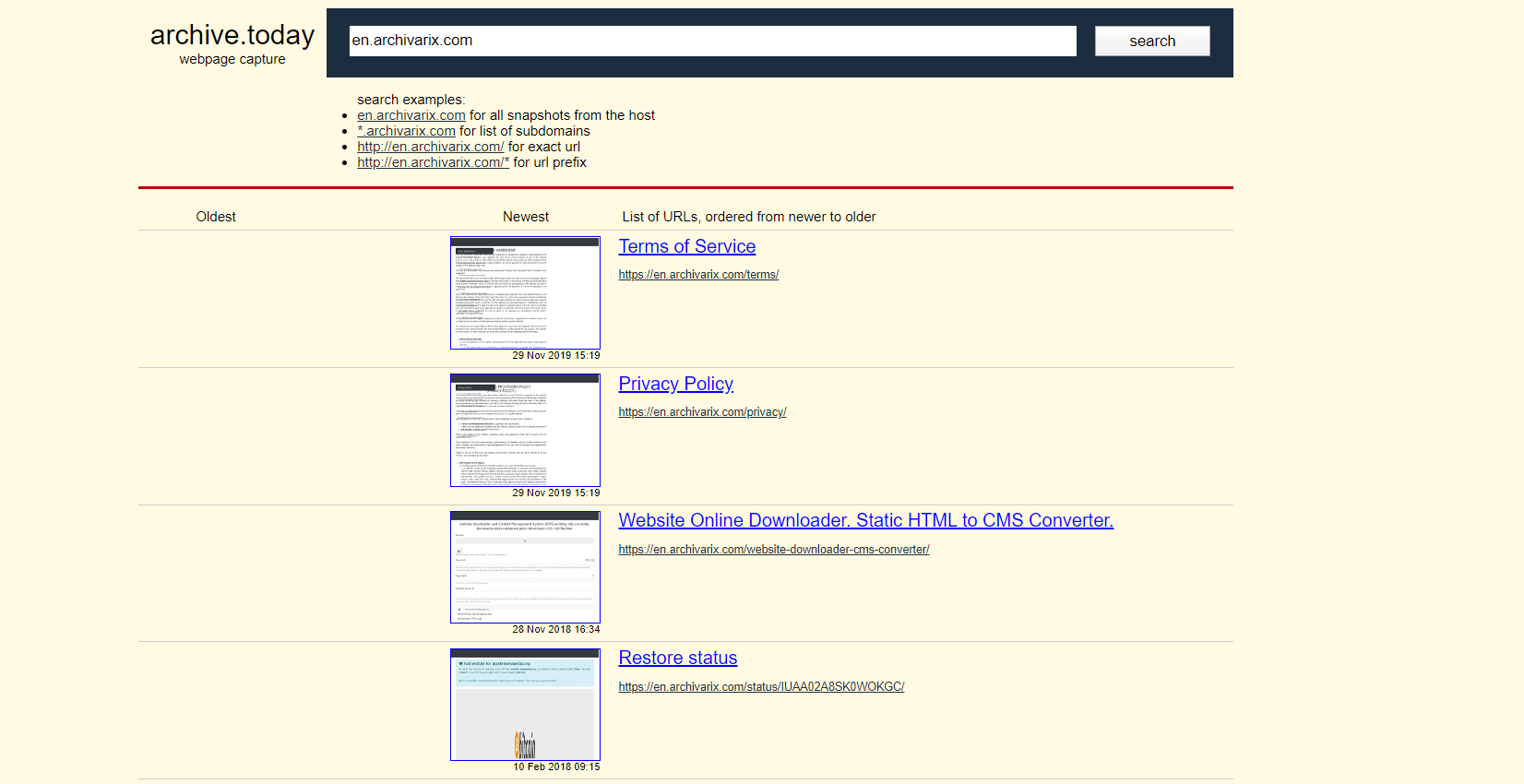
Аналоги web.archive.org. Как найти удаленные сайты?
Веб Архив ( Archive.org) - самый известный и самый большой архив сайтов в мире. На их серверах сейчас находится более 400 миллиардов страниц. Существуют ли какие-либо системы, аналогичные Archive.org?
Читать дальше…
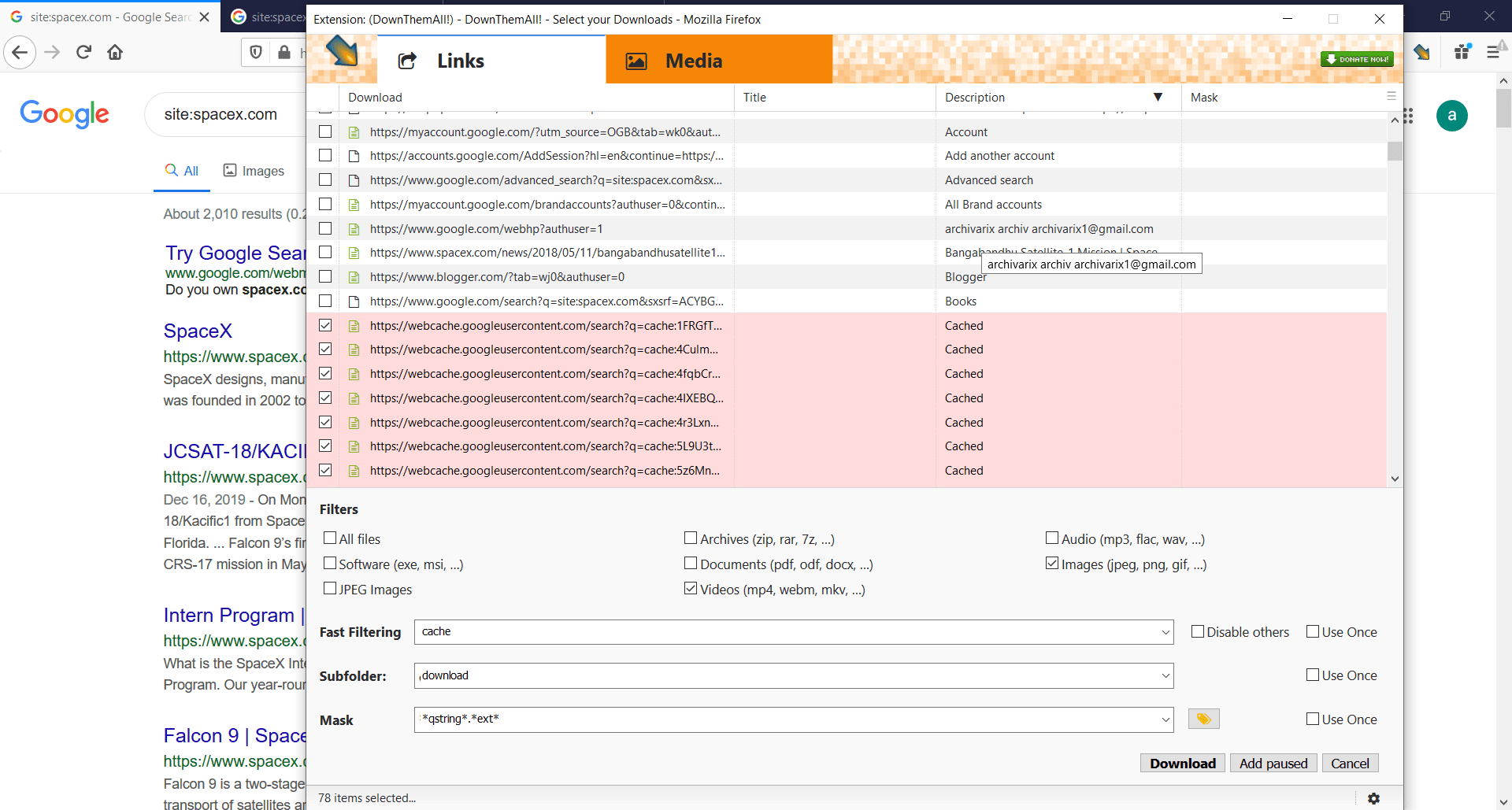
Как скачать сайт целиком из кэша Google?
Если нужный вам сайт был недавно удален, но Archive.org не сохранил последнюю версию, что можно сделать, чтобы получить его контент? Google Cache поможет это сделать. Все, что вам нужно, это установить вот такой плагин -
Читать дальше…
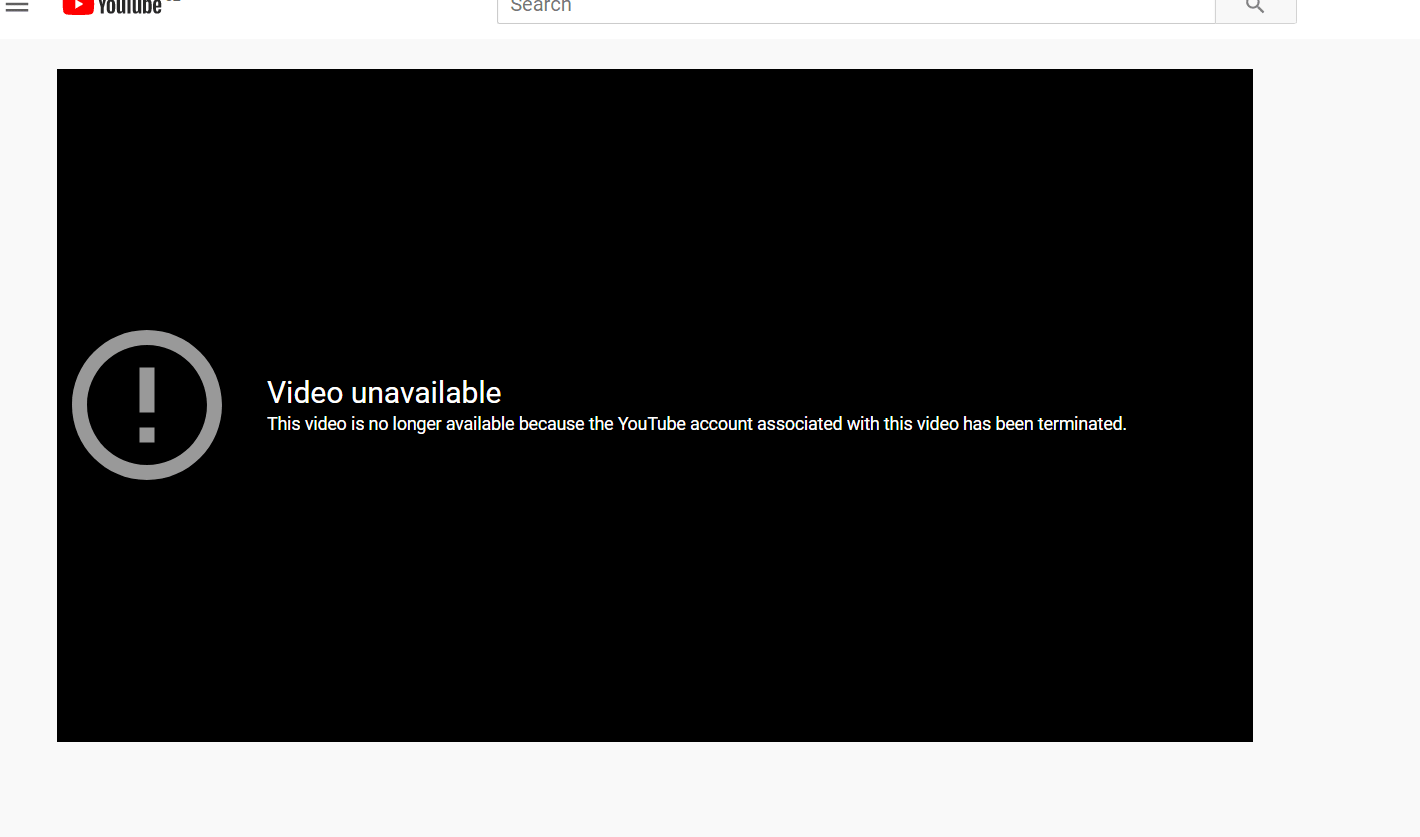
Как восстановить удаленные видео с YouTube?
Иногда вы можете увидеть это сообщение «Видео недоступно» на Youtube. Обычно это означает, что Youtube удалил это видео со своего сервера. Но есть простой способ, как получить его из Archive.org. Для начала вам нужна ссылка на видео с YouTube, она выглядит так: https://www.youtube.com/watch?v= 1vpS_-nN3JM Последние символы после watch?v= это код видео, который нам потребуется для восстановления.
Читать дальше…
Как спрятать от конкурентов обратные ссылки?
Известно, что анализ обратных ссылок конкурентов является важной частью работы СЕО оптимизатора. Если вы делаете сетку PBN блогов, то возможно вам не особо хотелось чтобы другие вебмастера знали, где вы размещаете свои ссылки. Анализом ссылочной массы занимается большое количество сервисов, самые известные из них Majestic, Ahrefs, Semrush. У всех них есть свои боты, которых можно заблокировать.
Читать дальше…
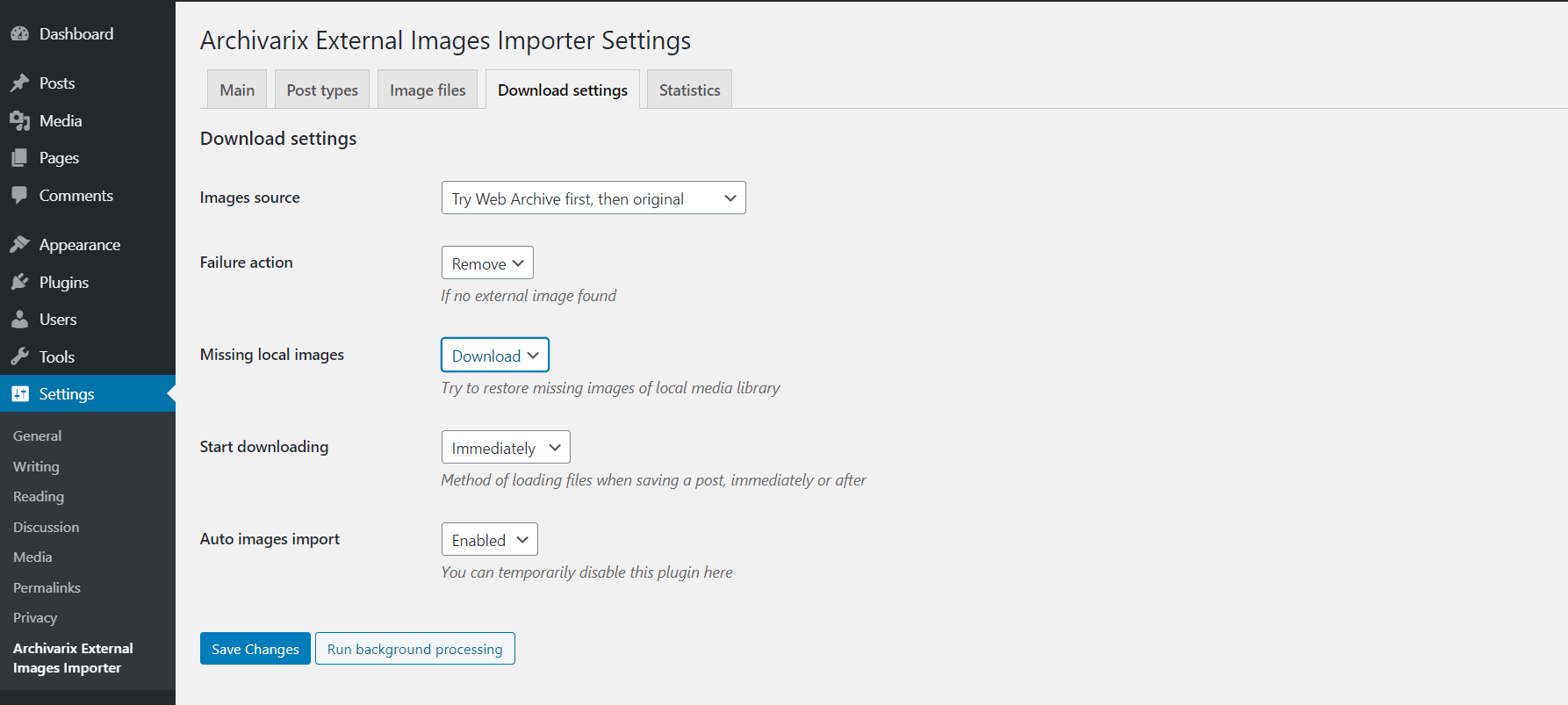
Как перенести контент из web.archive.org на Wordpress?
С помошью параметра "Извлечение структурированного контента" можно очень просто сделать Wordpress блог как из сайта, найденного в Веб Архиве, так и из любого другого сайта. Для этого находим сайт-источник, далее в инструменте Восстановить Сайт или Скачать сайт отмечаем опцию "Извлечь структурированный контент" и запускаем парсинг сайта.
Читать дальше…
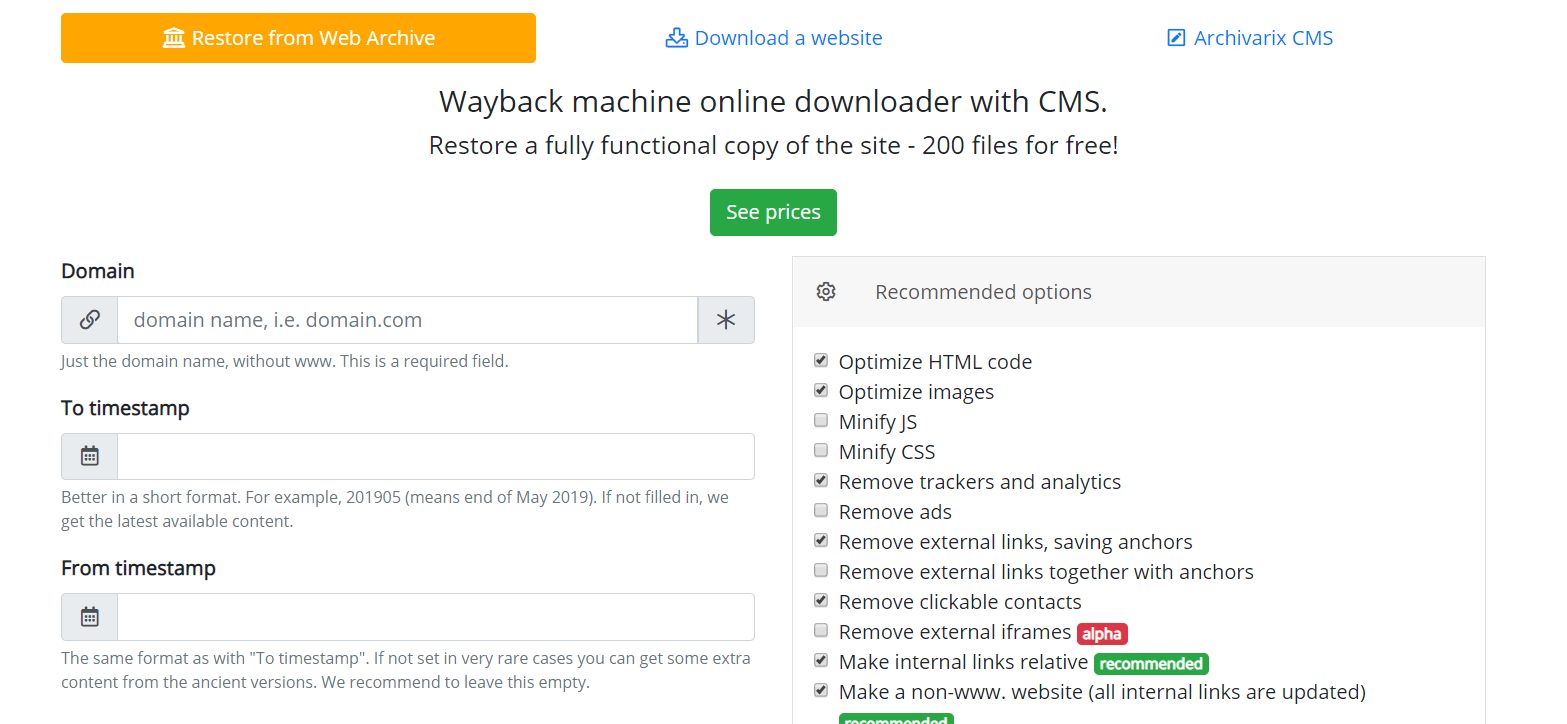
Как работает Архиварикс?
Система Архиварикс предназначена для скачивания и восстановления сайтов - как уже не работающих из Веб Архива, так и живых, находящихся в данный момент онлайн. В этом заключается ее основное отличие от прочих «качалок» и «парсеров сайтов». Задача Архиварикса - не только скачать, но и восстановить сайт в таком виде, в котором его можно будет использовать в дальнейшем на своем сервере.
Начнем с модуля, ответственного за скачивание сайтов из Веб Архива. Это виртуальные серверы, находящиеся в Калифорнии. Место расположения их было выбрано таким образом, чтобы получить максимально возможную скорость соединения с самим Веб Архивом, сервера которого расположены в Сан-Франциско. После ввода данных в соответствующих полях на странице модуля https://ru.archivarix.com/restore/ он делает скриншот архивного сайта и обращается к API Веб Архива с запросом списка файлов, содержащихся на указанную дату восстановления.
Читать дальше…
Начнем с модуля, ответственного за скачивание сайтов из Веб Архива. Это виртуальные серверы, находящиеся в Калифорнии. Место расположения их было выбрано таким образом, чтобы получить максимально возможную скорость соединения с самим Веб Архивом, сервера которого расположены в Сан-Франциско. После ввода данных в соответствующих полях на странице модуля https://ru.archivarix.com/restore/ он делает скриншот архивного сайта и обращается к API Веб Архива с запросом списка файлов, содержащихся на указанную дату восстановления.
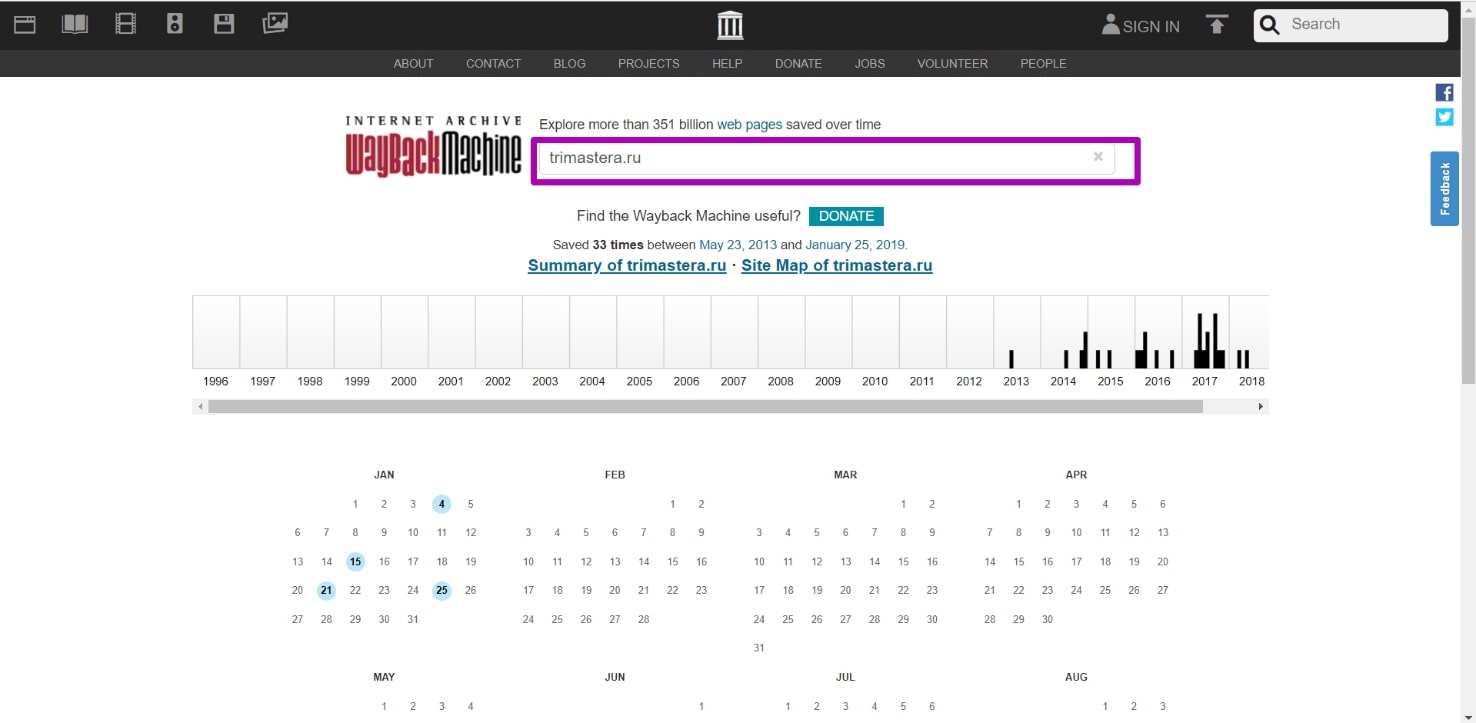
Как восстанавливать сайты из Веб Архива - archive.org. Часть 3
Выбор ограничения ДО при восстановлении сайтов из веб-архива. Когда домен заканчивается, на сайте может появится заглушка домен-провайдера или хостера. Перейдя на такую страницу, веб-архив будет ее сохранять, как полностью рабочую, отображая соответственную информацию в календаре. Если по такой дате из календаря восстановить сайт, то, вместо нормальной страницы мы получим ту самую заглушку. Как этого избежать и узнать дату работоспособности всех страниц сайта, по которой его можно восстановить?
Читать дальше…
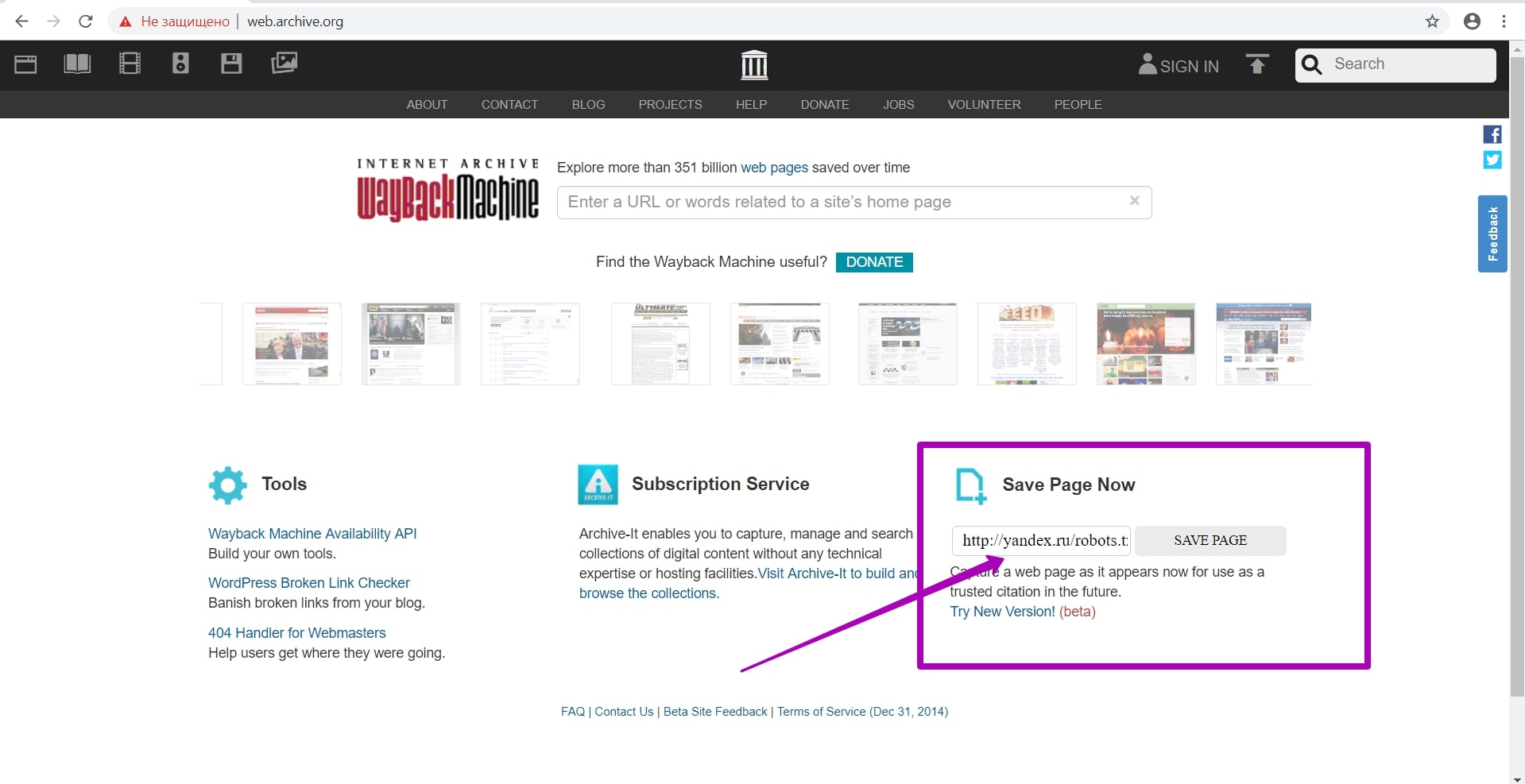
Как восстанавливать сайты из Веб Архива - archive.org. Часть 2
Подготовка домена к восстановлению. Создание robots.txt
В прошлой статье мы рассмотрели работу сервиса archive.org, а в этой статье речь пойдет об очень важном этапе восстановления сайта из веб-архива ― этапе подготовки домена к восстановлению. Именно этот шаг дает уверенность, что вы восстановите максимум контента на вашем сайте.
Читать дальше…
В прошлой статье мы рассмотрели работу сервиса archive.org, а в этой статье речь пойдет об очень важном этапе восстановления сайта из веб-архива ― этапе подготовки домена к восстановлению. Именно этот шаг дает уверенность, что вы восстановите максимум контента на вашем сайте.
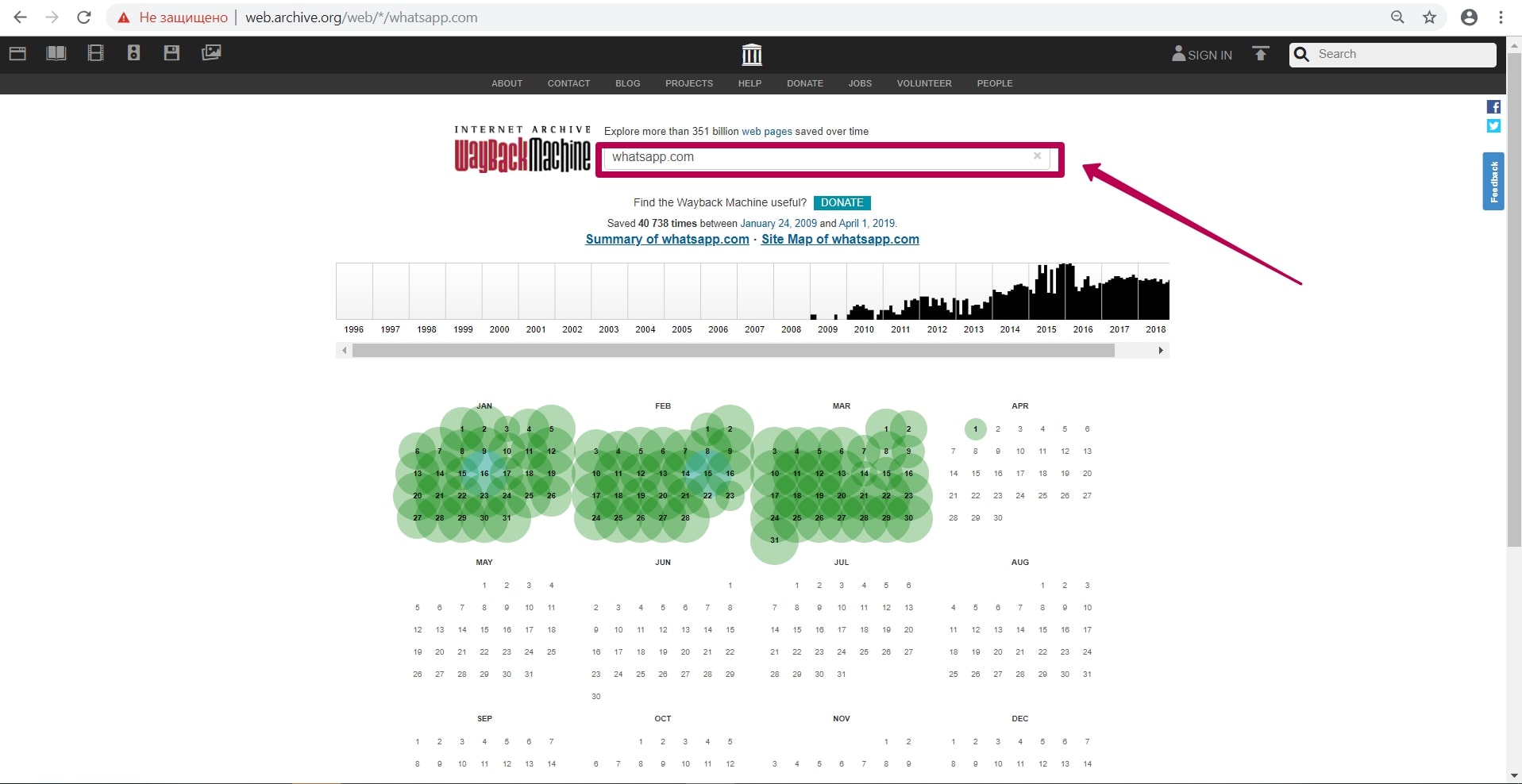
Как восстанавливать сайты из Веб Архива - archive.org. Часть 1
В этой статье мы расскажем о самом web.archive и о том, как он работает. Интерфейс веб-архива: инструкция к инструментам Summary, Explore и Site map. В этой статье мы расскажем о самом web.archive и о том, как он работает.
Читать дальше…

Последние новости:
2020.11.03
Новая верия CMS стала удобнее и понятее вебмастерам из разных стран мира.
- Полная локализация Archivarix CMS на 13 языков (Английский, Испанский, Итальянский, Немецкий, Французский, Португальский, Польский, Турецкий, Японский, Китайский, Русский, Украинский, Белорусский).
- Экспорт всех текущих данных сайта в zip архив для сохранения резервной копии или переноса на другой сайт.
- Показ и удаления битых zip архивов в инструментах импорта.
- Проверка версии PHP при установке.
- Информация для установки CMS на сервер с NGINX + PHP-FPM.
- В поиске при включенном режиме эксперта отображается дата/время страницы и ссылка на её копию в ВебАрхив.
- Улучшения пользовательского интерфейса.
- Оптимизация кода.
Если вы на уровне носителя владеете языком, на который наша CMS ещё не переведена, то приглашаем вас сделать наш продукт ещё лучше. Через сервис Crowdin вы можете подать заявку и стать нашим официальным переводчиком на новые языки.
- Полная локализация Archivarix CMS на 13 языков (Английский, Испанский, Итальянский, Немецкий, Французский, Португальский, Польский, Турецкий, Японский, Китайский, Русский, Украинский, Белорусский).
- Экспорт всех текущих данных сайта в zip архив для сохранения резервной копии или переноса на другой сайт.
- Показ и удаления битых zip архивов в инструментах импорта.
- Проверка версии PHP при установке.
- Информация для установки CMS на сервер с NGINX + PHP-FPM.
- В поиске при включенном режиме эксперта отображается дата/время страницы и ссылка на её копию в ВебАрхив.
- Улучшения пользовательского интерфейса.
- Оптимизация кода.
Если вы на уровне носителя владеете языком, на который наша CMS ещё не переведена, то приглашаем вас сделать наш продукт ещё лучше. Через сервис Crowdin вы можете подать заявку и стать нашим официальным переводчиком на новые языки.
2020.10.06
Новая верия Archivarix CMS.
- Поддержка интерфейса командной строки для развертывания веб-сайтов прямо из командной строки, импорта, настроек, статистики, очистки истории и обновления системы.
- Поддержка зашифрованных паролей password_hash(), которые можно использовать в CLI.
- Экспертный режим для включения дополнительной отладочной информации, экспериментальных инструментов и прямых ссылок на сохраненные снимки WebArchive.
- Инструменты для неработающих внутренних изображений и ссылок теперь могут возвращать список всех отсутствующих URL-адресов вместо удаления.
- Инструмент импорта показывает поврежденные / неполные zip-файлы, которые можно удалить.
- Улучшена поддержка файлов cookie, чтобы соответствовать требованиям современных браузеров.
- Настройка выбора редактора по умолчанию для HTML-страниц (визуальный редактор или код).
- Вкладка «Изменения», показывающая различия текста, по умолчанию отключена, может быть включена в настройках.
- Откатиться к конкретному изменению можно во вкладке «Изменения».
- Исправлен URL-адрес карты сайта XML для веб-сайтов, построенных с субдоменом www.
- Исправлено удаление временных файлов, которые были созданы в процессе установки / импорта.
- Более быстрая очистка истории.
- Удалены неиспользуемые фразы локализации.
- Переключение языка на экране входа в систему.
- Обновлены внешние пакеты до самых последних версий.
- Оптимизировано использование памяти для расчета текстовых различий на вкладке «Изменения».
- Улучшена поддержка старых версий расширения php-dom.
- Экспериментальный инструмент для исправления размеров файлов в базе данных, если вы редактировали файлы непосредственно на сервере.
- Экспериментальный и очень сырой инструмент экспорта плоской конструкции.
- Экспериментальная поддержка открытого ключа для будущих функций API.
- Поддержка интерфейса командной строки для развертывания веб-сайтов прямо из командной строки, импорта, настроек, статистики, очистки истории и обновления системы.
- Поддержка зашифрованных паролей password_hash(), которые можно использовать в CLI.
- Экспертный режим для включения дополнительной отладочной информации, экспериментальных инструментов и прямых ссылок на сохраненные снимки WebArchive.
- Инструменты для неработающих внутренних изображений и ссылок теперь могут возвращать список всех отсутствующих URL-адресов вместо удаления.
- Инструмент импорта показывает поврежденные / неполные zip-файлы, которые можно удалить.
- Улучшена поддержка файлов cookie, чтобы соответствовать требованиям современных браузеров.
- Настройка выбора редактора по умолчанию для HTML-страниц (визуальный редактор или код).
- Вкладка «Изменения», показывающая различия текста, по умолчанию отключена, может быть включена в настройках.
- Откатиться к конкретному изменению можно во вкладке «Изменения».
- Исправлен URL-адрес карты сайта XML для веб-сайтов, построенных с субдоменом www.
- Исправлено удаление временных файлов, которые были созданы в процессе установки / импорта.
- Более быстрая очистка истории.
- Удалены неиспользуемые фразы локализации.
- Переключение языка на экране входа в систему.
- Обновлены внешние пакеты до самых последних версий.
- Оптимизировано использование памяти для расчета текстовых различий на вкладке «Изменения».
- Улучшена поддержка старых версий расширения php-dom.
- Экспериментальный инструмент для исправления размеров файлов в базе данных, если вы редактировали файлы непосредственно на сервере.
- Экспериментальный и очень сырой инструмент экспорта плоской конструкции.
- Экспериментальная поддержка открытого ключа для будущих функций API.
2020.06.08
Первое июньское обновление Archivarix CMS с новыми, удобными фичами.
- Исправлено: Раздел История не работал при отсутствии включённого php расширения zip.
- Вкладка История с деталями изменений при редактировании текстовых файлов.
- Инструмент редактирования .htaccess.
- Возможность подчистить бэкапы до нужной точки отката.
- Блок "Отсутствующие урлы" убран из Инструментов, т.к. он доступен с главной панели
- В главную панель добавлена проверка и показ свободного места на диске.
- Улучшена проверка необходимых PHP расширений при запуске и начальной установке.
- Мелкие косметические правки.
- Все внешние инструменты обновлены на последние версии.
- Исправлено: Раздел История не работал при отсутствии включённого php расширения zip.
- Вкладка История с деталями изменений при редактировании текстовых файлов.
- Инструмент редактирования .htaccess.
- Возможность подчистить бэкапы до нужной точки отката.
- Блок "Отсутствующие урлы" убран из Инструментов, т.к. он доступен с главной панели
- В главную панель добавлена проверка и показ свободного места на диске.
- Улучшена проверка необходимых PHP расширений при запуске и начальной установке.
- Мелкие косметические правки.
- Все внешние инструменты обновлены на последние версии.
2020.05.21
Обновление, которое оценят веб-студии и те, кто использует аутсорс.
- Отдельный пароль для безопасного режима.
- Расширен безопасный режим. Теперь можно создавать кастомные правила и файлы, но без исполняемого кода.
- Переустановка сайта из CMS без необходимости что-либо вручную удалять с сервера.
- Возможность сортировать кастомные правила.
- Улучшены Поиск & Замена для очень больших сайтов.
- Дополнительные настройки у инструмента "Метатег viewport".
- Поддержка IDN доменов на хостингах со старой версией ICU.
- В начальной установке с паролем добавлена возможность разлогиниться.
- Если при интеграции с WP обнаружен .htaccess, то правила Archivarix допишутся в его начало.
- При скачивании сайтов по серийному номер используется CDN для повышения скорости.
- Другие мелкие улучшения и фиксы.
- Отдельный пароль для безопасного режима.
- Расширен безопасный режим. Теперь можно создавать кастомные правила и файлы, но без исполняемого кода.
- Переустановка сайта из CMS без необходимости что-либо вручную удалять с сервера.
- Возможность сортировать кастомные правила.
- Улучшены Поиск & Замена для очень больших сайтов.
- Дополнительные настройки у инструмента "Метатег viewport".
- Поддержка IDN доменов на хостингах со старой версией ICU.
- В начальной установке с паролем добавлена возможность разлогиниться.
- Если при интеграции с WP обнаружен .htaccess, то правила Archivarix допишутся в его начало.
- При скачивании сайтов по серийному номер используется CDN для повышения скорости.
- Другие мелкие улучшения и фиксы.
2020.05.12
Наша Archivarix CMS развивается семимильными шагами. Новое обновление, в котором появились:
- Новый дэшборд для просмотра статистики, настроек сервера и обновления системы.
- Возможность создавать шаблоны и удобным образом добавлять новые страницы на сайт.
- Интеграция с Wordpress и Joomla в один клик.
- Теперь в Поиске-Замене дополнительная фильтрация сделана в виде конструктора, где можно добавить любое количество правил.
- Фильтровать результаты теперь можно и по домену/поддоменам, дате-времени, размеру файлов.
- Новый инструмент сброса кэша в Cloudlfare или включения/отключения Dev Mode.
- Новый инструмент удаления версионности у урлов, к примеру, "?ver=1.2.3" у css или js. Позволяет чинить даже те страницы, которые криво выглядели в ВебАрхиве из-за отсутствия стилей с разными версиями.
- У инструмента robots.txt добавлена возможность сразу включать и добавлять Sitemap карту.
- Автоматическое и ручное создание точек откатов у изменений.
- Импорт умеет импортировать шаблоны.
- Сохранение/Импорт настроек лоадера содержит в себе созданные кастомные файлы.
- У всех действий, которые могут длиться больше таймаута, отображается прогресс-бар.
- Инструмент добавления метатега viewport во все страницы сайта.
- У инструментов удаления битых ссылок и изображений возможность учитывать файлы на сервере.
- Новый инструмент исправления неправильных urlencode ссылок в html коде. Редко, но может пригодиться.
- Улучшен инструмент отсутствующих урлов. Вместе с новым лоадером, теперь ведётся подсчёт обращений к несуществующим урлам.
- Подсказки по регулярным выражениями в Поиске & Замене.
- Улучшена проверка недостающих расширений php.
- Обновлены все используемые js инструменты на последние версии.
Это и много других косметических улучший и оптимизации по скорости.
- Новый дэшборд для просмотра статистики, настроек сервера и обновления системы.
- Возможность создавать шаблоны и удобным образом добавлять новые страницы на сайт.
- Интеграция с Wordpress и Joomla в один клик.
- Теперь в Поиске-Замене дополнительная фильтрация сделана в виде конструктора, где можно добавить любое количество правил.
- Фильтровать результаты теперь можно и по домену/поддоменам, дате-времени, размеру файлов.
- Новый инструмент сброса кэша в Cloudlfare или включения/отключения Dev Mode.
- Новый инструмент удаления версионности у урлов, к примеру, "?ver=1.2.3" у css или js. Позволяет чинить даже те страницы, которые криво выглядели в ВебАрхиве из-за отсутствия стилей с разными версиями.
- У инструмента robots.txt добавлена возможность сразу включать и добавлять Sitemap карту.
- Автоматическое и ручное создание точек откатов у изменений.
- Импорт умеет импортировать шаблоны.
- Сохранение/Импорт настроек лоадера содержит в себе созданные кастомные файлы.
- У всех действий, которые могут длиться больше таймаута, отображается прогресс-бар.
- Инструмент добавления метатега viewport во все страницы сайта.
- У инструментов удаления битых ссылок и изображений возможность учитывать файлы на сервере.
- Новый инструмент исправления неправильных urlencode ссылок в html коде. Редко, но может пригодиться.
- Улучшен инструмент отсутствующих урлов. Вместе с новым лоадером, теперь ведётся подсчёт обращений к несуществующим урлам.
- Подсказки по регулярным выражениями в Поиске & Замене.
- Улучшена проверка недостающих расширений php.
- Обновлены все используемые js инструменты на последние версии.
Это и много других косметических улучший и оптимизации по скорости.